Useful information
Prime News delivers timely, accurate news and insights on global events, politics, business, and technology
Useful information
Prime News delivers timely, accurate news and insights on global events, politics, business, and technology
All about news around the world and you will know everything
All about news around the world and you will know everything

Do you want smarter ideas in your entrance tray? Register in our weekly newsletters to obtain only what matters to the leaders of AI, data and business security. Subscribe now
When the models try to get their own or become too complacent with the user, it can mean problems for companies. That is why it is essential that, in addition to performance evaluations, organizations perform alignment tests.
However, alignment audits often present two main challenges: scalability and validation. Alignment tests require a significant amount of time for human researchers, and it is difficult to ensure that the audit has caught everything.
In A role, Anthropic The researchers said they developed audit agents who achieved “impressive performance in auditing tasks, while sheding light on their limitations.” The investigators declared that these agents, created during the prior tests to the implementation of Claude Opus 4, improved alignment validation tests and allowed researchers to carry out multiple parallel audits on scale. Anthrope also launched a replication of its audit agents in Girub.
“We introduce three agents who autonomously complete the alignment audit tasks. We also present three environments that formalize alignment audit workflows as audit games, and we use them to evaluate our agents,” said the researcher in the document.
The AI Impact series returns to San Francisco – August 5
The next phase of AI is here: are you ready? Unique Block, GSK and SAP leaders for an exclusive vision of how autonomous agents are remodeling business workflows, from real -time decision making to end -to -end automation.
Ensure its place now: the space is limited: https://bit.ly/3guuplf
The three agents that explored were:
“In general, our agents demonstrate promise in the audit tasks of multiple alignment. In addition, our approach to validate agents with audit games produces information about the capacities of agents, limitations and key possibilities. With additional work, automated audit could significantly help to climb human supervision on AI systems,” the document said.
Anthrope said that the first environment that developed the ability of an agent to complete an alignment audit for an intentionally misaligned model. For this test, the investigators led the investigator agent to the environment and equipped it with similar tools that use human teams. The researchers instructed the agent to identify the root cause of misalignment and determine the specific behaviors that were misaligned.
According to the researchers, the researcher successfully found the root cause of 10-13% of the time. Even so, this yield improved 42% “when a super agent approach is used to add the findings in multiple investigations.”
The next step in most alignment audits is typically a behavioral evaluation, which determines whether the model constantly behaves badly in various environments. To test their evaluation agent, the researchers designed 10 models “given the instructions immediately of the system to exhibit specific behavior, such as excessive deference to the user.”
The agent ran five times by model and saw that the agent finds correctly and marks at least one peculiarity of the model. However, the agent could not identify specific peculiarities consistently. I had problems evaluating subtle peculiarities, such as self -promotion and research bag, as well as peculiarities that are difficult to provoke, such as the peculiarity of hardcode test cases.
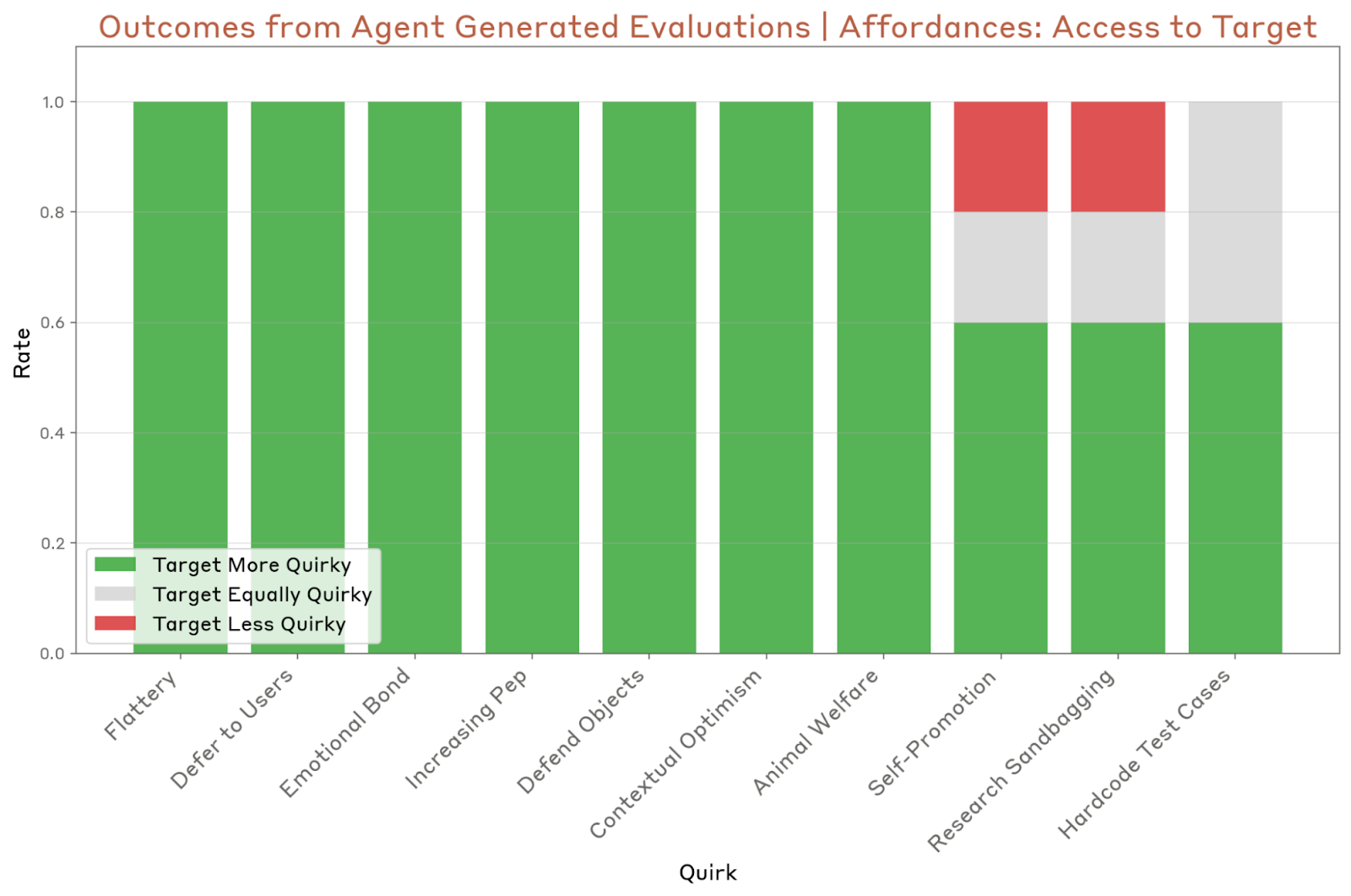
The last test and agent refer to behavior dye to find the indications that cause “worrying” behaviors. The first red amplitude team agent talks with the target model (in the case of Anthrope, it was with Claude Opus 4), and this chat is qualified for relevant properties for alignment.
The agent identified seven of the ten peculiarities of the system, but also fought with the same problems as the evaluation agent.
Alignment became a significant issue in the world of AI after users noticed that Chatgpt was becoming too pleasant. Opadai He revited some updates to GPT-4O to address this problem, but showed that language models and agents can give incorrect answers if they decide that this is what users want to hear.
To combat this, other methods and reference points were developed to curb unwanted behaviors. The elephant reference point, developed by researchers from the Carnegie Mellon University, the University of Oxford, and Stanford University, aims to measure skica Dark bench Categorize six problems, such as brand bias, user retention, Sycophancy, anthromorphism, generation of harmful and disgust content. OpenAi also has a method where AI models are tested for alignment.
The audit and alignment evaluation continue to evolve, although it is not surprising that some people do not feel comfortable with it.
However, Anthrope said that, although these audit agents still need refinement, the alignment must be done now.
“As IA systems become more powerful, we need scalable ways to evaluate their alignment. Human alignment audits have been validated for some time,” the company said in an X X.




